
{kind=link}
Autore: Richie Koch, Proton | Pubblicazione originale: 27/01/2023 | Tradotto da: 31febbraio | Milano Trustless | Link: ChatGPT, AI, and the future of privacy
Il primo mese del 2023 ha portato brutali licenziamenti da parte di Big Tech, un potenziale ban di TikTok negli stati uniti e un'altra violazione di Twitter. Ma il più grande sviluppo di questo nuovo anno è l'ascesa di ChatGPT.
La chatbot è in grado di produrre un testo dall'aspetto umano e, a seconda delle richieste, di generare risposte creative che non sembrano provenire da un computer:
having a particularly bizarre morning thanks to chatgpt pic.twitter.com/BX0cJUMVzn
— juan (@juanbuis) December 1, 2022
Il ritmo del progresso è sbalorditivo. E, se la tecnologia del passato è un esempio, non potrà che accelerare. L'attuale generazione di chatbot ha già infranto il test di Turing, rendendo molto probabile che i chatbot alimentati dall'intelligenza artificiale saranno presto applicati a tutti i tipi di lavori, attività e dispositivi nel prossimo futuro. È solo questione di tempo prima che l'interazione con l'IA diventi una parte regolare della nostra routine quotidiana. Questa proliferazione non farà che accelerare ulteriormente lo sviluppo dell'IA.
Sono tutte buone notizie! L'IA è uno strumento potente che potrebbe portare a ogni sorta di nuovi sviluppi e scoperte. Tuttavia, come per ogni strumento, dobbiamo assicurarci che sia usato e sviluppato in modo responsabile. Noi di Proton abbiamo notato che, a fronte di tutta la pubblicità che è stata fatta su ChatGPT, non sono state prese in considerazione le questioni relative alla privacy che l'IA solleva.
Spiegheremo come l'IA, come ChatGPT, abbia bisogno di dati per svilupparsi e come l'IA in futuro possa presentare nuove sfide alla nostra privacy.
Abbiamo anche intervistato ChatGPT sul futuro della privacy, e ha fornito alcune buone risposte.
It’s #DataPrivacyWeek & #AI has officially captured the world’s attention. But what does this mean for privacy? We've interviewed @OpenAI's #ChatGPT for its opinion.
— Proton (@ProtonPrivacy) January 27, 2023
Over the next 3 days, follow #ProtonTalksToChatGPT to watch our 15-part mini-video series.
Here’s part 1 / 15 pic.twitter.com/1WX7rW5whx
Nei prossimi giorni potrete vedere altri video della nostra conversazione con ChatGPT.
L'addestramento dell'IA richiede dati. Una mole gigantesca di dati
Per addestrare e migliorare la maggior parte dei modelli di IA sono necessarie enormi quantità di dati. Più dati vengono immessi nell'IA, più questa è in grado di rilevare modelli, anticipare ciò che accadrà in seguito e creare qualcosa di completamente nuovo. Il processo è simile a questo:
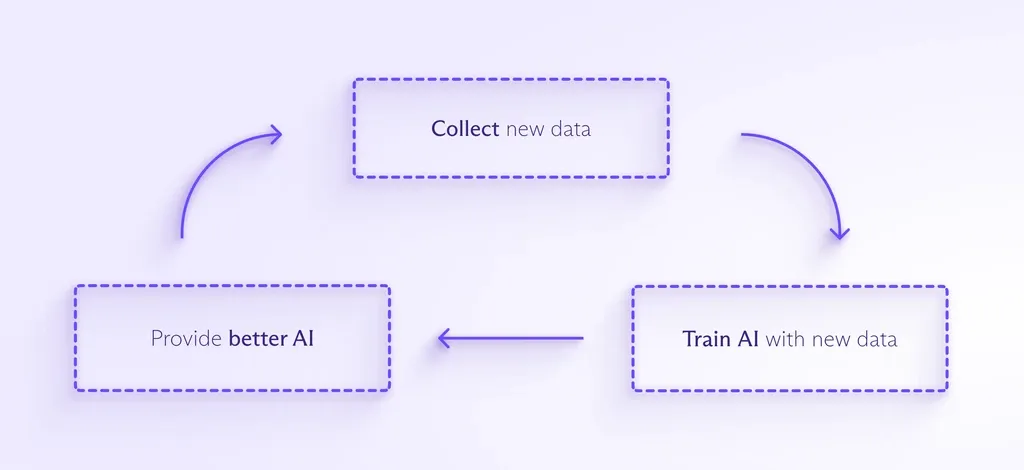
Man mano che l'IA viene integrata in un numero maggiore di prodotti rivolti ai consumatori, ci sarà una pressione per raccogliere ancora più dati per addestrarla. E poiché le persone interagiscono sempre più spesso con l'IA, è probabile che le aziende vogliano raccogliere i vostri dati personali per aiutare l'assistente IA a capire come dovrebbe rispondere a voi, nello specifico.
Questo comporta problemi di ogni tipo. Un'IA addestrata sui dati imparerà a gestire solo le situazioni che si presentano in base al set di dati che ha visto. Se i dati non sono rappresentativi, l'IA riprodurrà tale pregiudizio nel suo processo decisionale, come ha visto Amazon quando il suo bot di reclutamento IA ha penalizzato le candidate donne dopo essere stato addestrato sui curriculum in un set di dati a prevalenza maschile.
Allo stesso modo, se l'IA si imbatte in una situazione che non ha mai visto nei suoi dati di addestramento, potrebbe non sapere cosa fare. È il caso di un veicolo Uber a guida autonoma che ha ucciso un pedone che non è riuscito a identificare poiché la persona si trovava al di fuori delle strisce pedonali.
Prima che un'intelligenza artificiale possa essere addestrata sui dati, questi devono essere puliti, il che significa formattarli correttamente e cancellare contenuti razzisti, sessisti, violenti o discutibili. Proprio come la moderazione dei contenuti per aziende come Meta, questo compito è tipicamente estenuante, mal pagato e nascosto al pubblico. Recentemente è emerso che OpenAI si è affidata a centinaia di lavoratori mal pagati in Kenya per ripulire i dati di GPT-3.
Affinché l'IA eviti questi tipi di pregiudizi e punti ciechi, le aziende dovranno raccogliere ancora più dati di quelli che le Big Tech attualmente raccolgono per vendere annunci personalizzati. Forse non lo sapete, ma questi sforzi sono già iniziati.
Come esempio della scala di cui stiamo parlando, l'intera Wikipedia inglese, che comprende circa 6 milioni di articoli, ha costituito solo lo 0,6% dei dati di addestramento per il GPT-3, di cui ChatGPT è una variante.
Un esempio più noto è Clearview AI, che ha raccolto le immagini delle persone dal web e le ha utilizzate per addestrare la sua intelligenza artificiale per la sorveglianza facciale senza il permesso delle persone. Il suo database contiene circa 20 miliardi di immagini.
Clearview ha ricevuto cause legali di ogni tipo, multe e ordini di cessazione dell'attività per il suo palese disprezzo della privacy delle persone. Tuttavia, è riuscita a non pagare molte multe e ha respinto le ingiunzioni a cancellare i dati nonostante gli ordini delle autorità di regolamentazione, aprendo potenzialmente una strada che altri sviluppatori di IA senza scrupoli potrebbero seguire.
Un'altra preoccupazione è che l'ubiquità dell'IA possa rendere quasi impossibile evitare la raccolta di dati.
L'IA ascolterà il vostro caso ora
Oggi siamo preoccupati per la quantità di dati che le Big Tech raccolgono da noi mentre navighiamo online o tramite dispositivi smart connessi a Internet. Tuttavia, il numero di dispositivi e la quantità di dati complessivamente raccolti saliranno alle stelle con il miglioramento dell'IA e dei chatbot. Inoltre, l'IA inizierà a prendere il sopravvento su porzioni della nostra vita che sono già dominate dagli algoritmi, rendendo impossibile sfuggirvi.
Attualmente, a seconda del luogo in cui si vive, un algoritmo potrebbe decidere se si si può usufruire di una cauzione prima del processo, se si ha diritto a un mutuo per la casa e quanto si paga per l'assicurazione sanitaria. L'intelligenza artificiale si occuperà di questi compiti essenziali e probabilmente si espanderà in altri settori. Sembra che ci sia una ricerca infinita per usare l'IA per prevedere i crimini. Sono già stati condotti esperimenti utilizzando il GPT-3 come chatbot medico (con risultati disastrosi).
Man mano che l'IA viene applicata a nuove funzioni, sarà esposta a un numero sempre maggiore di informazioni sensibili e diventerà sempre più difficile per le persone evitare di condividere le proprie informazioni con l'IA. Inoltre, una volta raccolti i dati, è molto facile che vengano riutilizzati o usati per qualcosa a cui le persone non hanno mai acconsentito.
Non sappiamo come sarà l'IA in futuro
Nel 1965 i computer occupavano intere stanze. In quell'anno Gordon Moore elaborò la cosiddetta Legge di Moore, secondo la quale il numero di transistor che possono essere inseriti in un circuito integrato raddoppia ogni due anni. La sua previsione si è dimostrata straordinariamente accurata per oltre 40 anni e si è interrotta solo di recente. Ma nemmeno lui avrebbe potuto prevedere quanto siano avanzati i nostri computer attuali.
Molto probabilmente guarderemo al ChatGPT nello stesso modo in cui guardiamo un computer degli anni '60 e ci stupiremo di come qualcuno sia stato in grado di fare qualcosa con esso. Il fatto è che siamo all'inizio di un viaggio tecnologico epocale e non abbiamo idea di dove ci porterà.
Siamo preoccupati di come le piattaforme di Big Tech possano influenzare sottilmente il nostro processo decisionale e creare bolle di filtraggio impossibili da evitare. Tuttavia, questi potrebbero sembrare strumenti spuntati rispetto a un motore di ricerca o a un nuovo servizio alimentato dall'intelligenza artificiale. Inoltre l'IA potrebbe diventare così brava nel riconoscimento dei modelli da sviluppare la capacità di de-anonimizzare i dati o di abbinare le identità tra insiemi di dati diversi. Tutto questo suona speculativo, ma è semplicemente perché non abbiamo idea di quali siano i limiti superiori delle capacità dell'IA.
Cosa possiamo fare per preservare la privacy in un futuro basato sull'IA?
La buona notizia è che ci sono cose che possiamo fare fin da ora per garantire che l'IA venga addestrata in modo responsabile utilizzando dati anonimizzati. Abbiamo in programma di scrivere un altro articolo in futuro sui metodi che le aziende possono utilizzare per addestrare l'IA su set di dati proteggendo al contempo la privacy delle persone.
Se siete preoccupati per la vostra privacy, non è mai troppo presto per iniziare a proteggere le vostre informazioni. Se crittografate i vostri dati (con servizi come Proton Mail o Proton Drive), li rimuoverete dalle Big Tech o dai database pubblici, impedendo che vengano utilizzati per tracciarvi o per addestrare l'intelligenza artificiale.
Potete anche usare siti come Have I Been Trained per vedere se qualcuna delle vostre immagini è già stata usata per addestrare l'IA. Purtroppo, anche se scoprite che una delle vostre immagini è stata usata senza il vostro permesso, non è sempre facile capire come farla rimuovere.
Per quanto riguarda i responsabili politici, essi possono iniziare a definire quadri di riferimento per l'uso dell'IA che sanciscano il diritto alla privacy. Ma dobbiamo agire subito. L'IA si svilupperà probabilmente a un ritmo esponenziale, il che significa che dobbiamo rispondere a queste domande ora, prima che sia troppo tardi.
La prima cosa che si può fare è che ogni paese approvi una legge sulla privacy dei dati che limiti quali tipi di dati personali possono essere raccolti e per quali scopi possono essere legalmente utilizzati. In questo modo sarebbe più facile reprimere aziende come Clearview AI.
In prospettiva, i politici possono richiedere che le aziende di IA forniscano trasparenza su come funzionano i loro algoritmi e modelli di IA, o almeno sui set di dati che utilizzano per addestrare i loro sistemi. Questo aiuterà le aziende a non perpetuare i pregiudizi e i punti ciechi dell'IA di cui abbiamo parlato in precedenza.
I politici dovrebbero anche obbligare le aziende di IA a sottoporre i loro modelli a verifiche periodiche e a dotarsi di responsabili della privacy dei dati indipendenti per assicurarsi che i dati vengano utilizzati in modo responsabile.
Questo è un momento emozionante nella storia dell'umanità. L'IA è una frontiera inesplorata, ma prima di avventurarci dobbiamo assicurarci di aver garantito i nostri diritti umani fondamentali.